
2. 源码解析
上一篇文章 Java集合—HashMap之resize方法 已经讲完了 HashMap 的扩容方法了,之前讲 HashMap 的文章中在遇到红黑树相关的部分都跳过了,那么这篇文章就把之前留下的坑填起来。
2.5 红黑树
2.5.1 多大的数据量会转化为红黑树?
我们首先想一想,为了降低 hash 冲突,HashMap 已经对 hash 算法进行了优化,而且我们使用的负载因子 0.75 已经能够保证及时的进行扩容,其实链表的长度超过 8 是一件很难的事情。那么在实际的使用过程中,出现红黑树的概率很小。只有当数据量及其庞大的时候,才可能会出现树化(链表转红黑树)。
那么到底多大的数据量会出现呢?我闲来无事做了个试验。
1 | public class HashMapDemo { |
如上述代码所示,循环一亿次,每次随机生成 key ,我在 HashMap 的 putVal 方法中的 treeifyBin(tab, hash) 这行代码打个断点,debug 一下,看什么时候会进入这个断点,就能看的什么时候进行树化,并记录下此时 size 的值。如下面截图所示:


此时,size 的值 为 1528475,即往 HashMap 中插入 1528475 条数据才会出现链表转化为红黑树。我们执行十次,最终记录的十次 size 如下所示:
1528475、5654463、6267869、1495463、9770744、
2869246、2839446、2812804、1327125、4950783。
可以看出,只有在几百万数据量的时候,才会转化为红黑树。
这个时候我们想一想,有谁会在 HashMap 中存入几百万的数据?我们知道,Spring 存储 bean 用的是 ConcurrentHashMap,Eureka 存储服务注册实例也是用的 ConcurrentHashMap ,RocketMQ 的 NameServer 存储路由元数据是用的 HashMap 。
在开源框架里面,HashMap/ConcurrentHashMap 作为内存存储数据非常常见。但是不会在 Spring 中出现几百万个 bean,也不会注册几百万个服务实例到 Eureka,更不可能有几百万个 Broker 注册到 NameServer 中。
综上所示,HashMap 的红黑树只有在极少场景下才可能会用到。但是呢,原理我们还是要研究滴!
2.5.1 为什么是8和64?
我们来回忆下,在链表的长度大于等于 8 并且数组的长度大于等于 64 时,链表才会转化为红黑树。那为什么是 8 呢?我们接下来慢慢讲。
首先思考一个问题:为什么要转化为红黑树?如果只是用链表会有什么问题?其实原因很简单,红黑树查询比链表快,如果 hash 冲突很严重,链表长度过长,会导致查询很慢。
那再思考一个问题:既然红黑树查询快为什么还要链表,直接数组 + 红黑树不香吗?原因是红黑树查询快,但是插入慢,每次插入都可能伴随着节点的变色或者旋转,而且存储红黑树需要的内存比链表大。这就需要我们在存储空间和查询时间之间做一个平衡了,这个很符合中国人的中庸之道嘛。
还记得之前文章中写的负载因子 0.75 的来历吗?0.75 就是官方在时间和空间上取的一个平衡。那这个 8 是不是也是取的一个平衡呢?
来,我们来看看源码注释:
1 | * Because TreeNodes are about twice the size of regular nodes, we |
简单翻译一下:TreeNodes 占用的内存是普通 Node 的两倍,只有在 node 数量达到阈值时才会使用它,阈值就是 TREEIFY_THRESHOLD 。而当 node 数量变小时(删除或者扩容),又会变回普通的 Node 。当 hashCode 的均匀分布的时候,TreeNode 是很少使用的。理想情况下,hashCode 的值遵循泊松分布。bala bala bala。。。
之后官方推导出了一个数学公式,不好意思,我也看不懂了,也没必要去研究数学公式了。最终的结果就是当为 8 时的概率为 0.00000006 ,小于千万分之一。官方认为这个概率足够的低,所以指定链表长度为 8 时转化为红黑树。所以 8 这个数是经过数学推理的,不是瞎写的。
从我们上面的试验也能看出来,平均几百万才会出现链表转化为红黑树(和官方理论值千万稍微有点不一致)。
那为什么树化的时候还要满足数组的长度大于等于 64 呢?我们来看看源码注释:
1 | /** |
翻译一下注释:64 是最小的树化时的数组容量,如果小于 64 ,优先考虑使用扩容降低冲突。
这里我的理解是,在数组容量小时,扩容的频率本身就很高,而且容量小时,在某个数组位置出现 hash 冲突的概率肯定大于容量大时。此时进行扩容操作的话,会降低该数组位置冲突的个数,减小链表长度,就不用转化为红黑树了。
那这个时候,是不是又有人会问了,为什么是 64 呢?40 行不行,80行不行?
额。。。这一点官方文档和源码并未给出任何说明,只是说必须大于 4 * 8 = 32,然后官方取了 64。我猜这应该也是个统计数学的问题,就不过多纠结了。
2.5.2 TreeNode
到现在为止,之前写的文章,无论是 hash 优化算法,还是 put 方法中数组转化为链表,还是 resize 方法中的 rehash ,我们研究的都是 putValue 方法,而 putValue 方法中有两处和红黑树相关。
- treeifyBin 方法,链表转红黑树的方法
- putTreeVal 方法,已经产生红黑树之后,往里面添加元素的方法
putTreeVal 方法已经完全是操作红黑树新增节点了,这个已经超越了我们分析 HashMap 的界限了,我们就不详细说了。其实是本人能力有限,还没有达到能手撕红黑树的地步,所以就一带而过好了(委屈脸)。
2.5.3 treeifyBin方法
接下来,我们来简单分析下 treeifyBin 方法。
1 | final void treeifyBin(Node<K,V>[] tab, int hash) { |
第 3~4 行代码其实就是判断数组长度是否满足 64,如果不满足,进行扩容,而不是进行树化。
然后进入到一个循环,遍历整个链表。老规矩,我们边画图,边分析。假设这个时候 HashMap 的底层结构如下图所示(链表太长,我直接用 Node1 ~ Node8 进行命名了):

这个时候,数组 index 为 1 的位置后面挂了长度为 8 的链表,并且数组长度为 64,满足要求,进行链表转红黑树。
首先进入第 8 行代码,通过 replacementTreeNode 方法将一个普通的 Node 转化为 TreeNode ,此时指针 e 指向的 “1-赵小发”,就是对这个 Node 进行转化,转化后新生成的对象我们统一用红色 “TreeNode” 字样进行标识。p 指针指向新生成的对象,因为此时 tl 指针为 null ,所以进入第 10 行代码,hd 指针也指向新生成的对象。同样执行到第 15 行代码,tl 指针也指向新生成的对象。最后图就是变成下面这样子:

然后执行第 16 行代码,e = e.next ,就变成了下面这张图。为了方便,我这里只截取了相关部分的图。
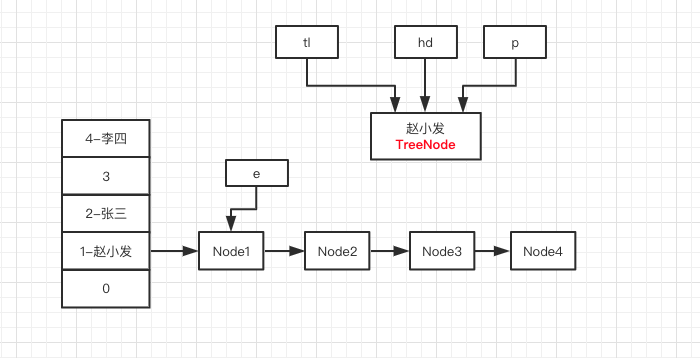
此时 e 不为 null ,继续循环。
再次进入第 8 行代码,此时转化的就是 Node1 节点了,此时 p 指针指向新创建的 TreeNode 对象,此时 tl 不为 null ,执行 第 12 ~ 13 代码,执行完毕之后如下图所示:
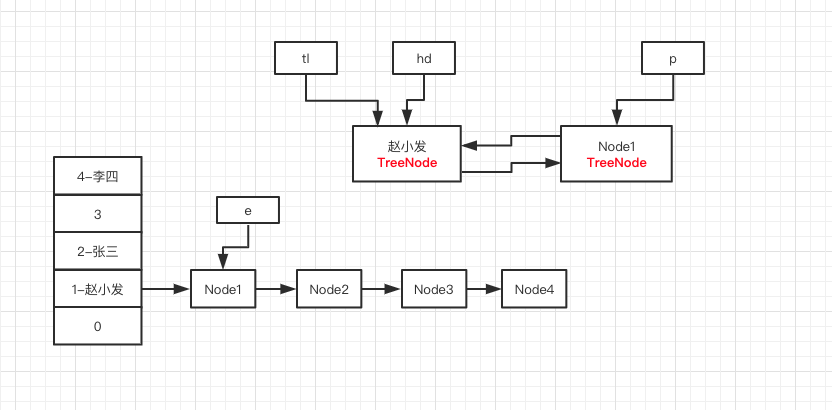
再执行第 15 行代码以及 16 行的 e = e.next ,tl 指针指向了新对象 ,e 指针指向 Node2 ,如下图所示:
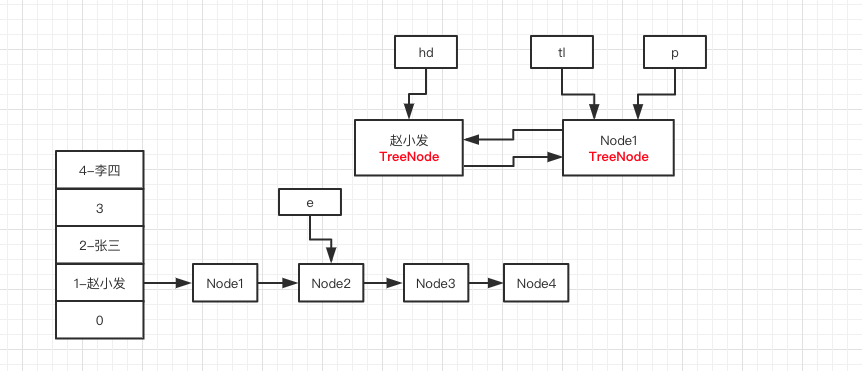
如此一直循环下去,会一直创建 TreeNode 并最终生成一个双向链表,而 e 指针一直往后指,最终指向 Node8 。最终图大致如下:
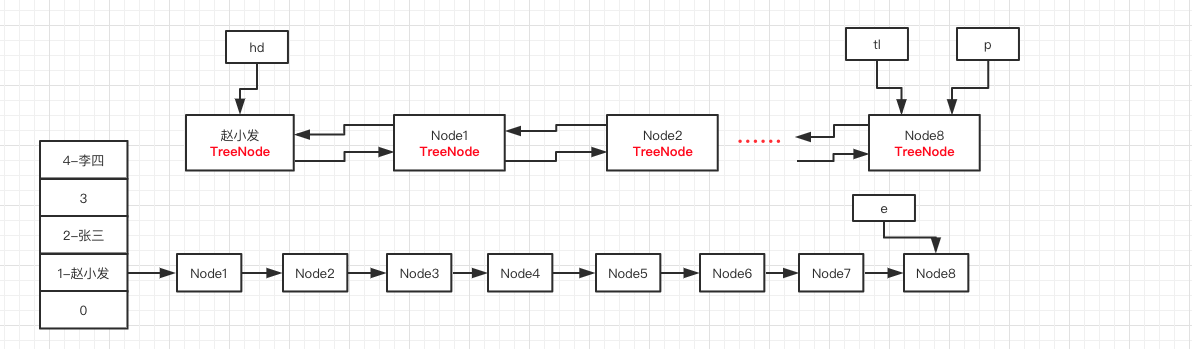
此时 e.next 指向 null ,退出循环。
执行第 17 行代码,tab[index] 此时就是数组 index 为 1 的位置,指向 hd 就变成了下面这样子了。

最后执行第 18 行代码 hd.treeify(tab) 。这个方法是将双向链表转化为红黑树。 转化过程也是红黑树的相关操作,我这里就不详细说明了。
小结:关于红黑树,其实很复杂,也没有必要去手撕;关于红黑树在 HashMap 中的使用,其实主要搞清楚,为什么要用,什么时候转化为红黑树大致就可以了。
3. 总结
HashMap 相关的四篇文章暂时就写到这了,核心的差不多也就这些了。我们再回顾下之前的几篇文章讲到的内容。
- 基本的底层数据结构、常用构造函数、负载因子为何取 0.75以及hash 优化算法。
- 详细介绍了 put 方法,出现 hash 冲突时,是如何一步一步形成链表的。
- 什么时候会扩容,扩容的时候原先链表上的元素会被放到新数组的哪个位置?
- 什么时候会转化为红黑树?链表上普通 Node 是先转化为 TreeNode 类型的双向链表再转化为红黑树的 。
有兴趣的同学还可以去研究下面几点:
- HashMap 在遍历的时候是怎么保证每次遍历的结果的顺序都是一致的,当然这个顺序并不是和插入的顺序相同的。
- 在扩容的时候红黑树又是怎么处理的,其实红黑树的节点之间也是使用了 next 指针和 prev 指针保存了原先链表的顺序,这样在扩容 rehash 时可以直接把它当做链表一样处理,就不需要先转化成链表再 rehash 了。
往深了研究,HashMap 其实是很复杂的。由于本人能力有限,就到此结束啦!(撒花)