
1. 前言
Topic 是一个逻辑概念,Partition 和 Segment 都是物理概念(有真实的日志文件)。
一个 Topic 可以认为是一类消息,每个 Topic 将被分成多个 Partition,每个 Partition 在存储层面是 log 日志文件。
任何发布到某个 Partition 的消息都会被追加到 log 文件的尾部,每条消息在文件中的位置称为 Offset(偏移量),写入操作是磁盘顺序写,比随机写的性能高很多。
Topic 和 Partition 的关系图如下所示(图片来自于 Kafka 官方文档):
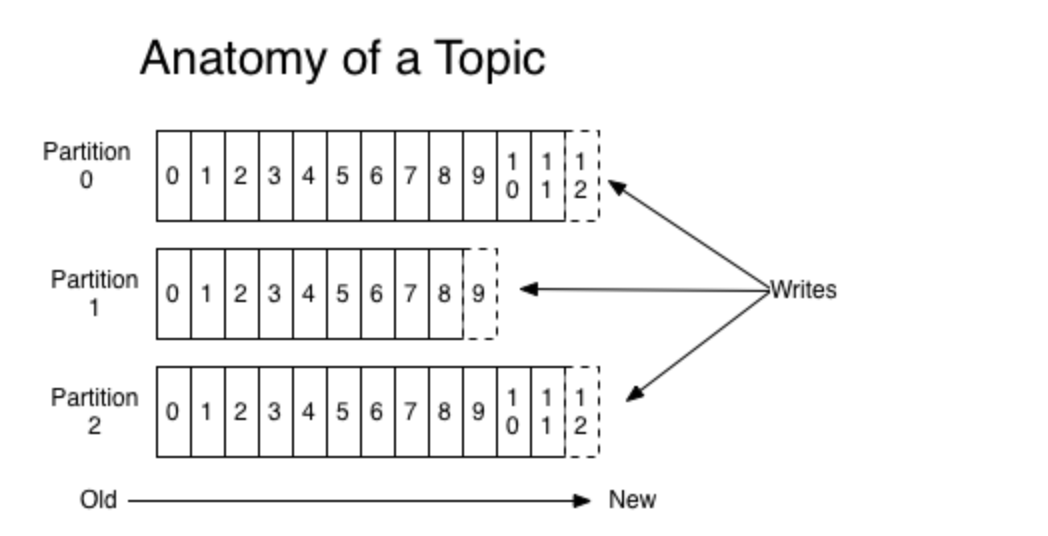
2. 为什么将 Topic 分成多个 Partition?
原因:负载均衡 + 水平扩容
如果不对 Topic 进行分区,将 Topic 的消息存储于一个 Broker,那么关于该 Topic 的所有读写请求都将由这一个 Broker 处理,如果 Topic 的消息量差距很大(非常常见),那么 Broker 的负载会及其不均。
如下图示例:
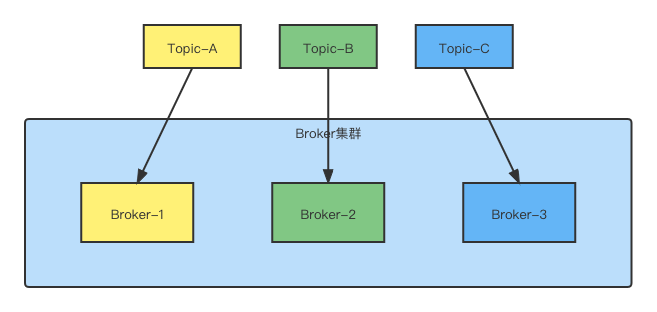
如果 Topic-A 消息量 50000/s,Topic-B 消息量 5000/s,Topic-C 消息量 1/s(这三个 Topic 的消息量取自于我负载的实际业务中),Broker 的流量很明显机器不均,对应机器系统水位天差地别。很明显,这不是我们希望的结果。
同理,此种架构无法支持水平扩容,如果 Topic-A 的流量增长到 100万/s,一个 Broker 节点是如何也扛不住的。
因为,需要引入Partition ,假设一个 Topic 被分为 4 个 Partitions,Kafka 会根据一定的算法将 4 个 Partition 尽可能均匀的分布到不同的 Broker 上,极大的提高吞吐量,并且使得系统具备良好的水平扩展能力。
3. Segment 存在的意义是什么?
Partition 并不是最终的存储粒度,Partition 还可以细分为 Segment,一个 Partition 物理上由多个 Segment 组成的。
3.1 测试
按照官网上的说明,我创建了一个测试 Topic,Partition 数量设置为 4,创建之后,在 /tmp/kafka-logs 目录下可以看到对应的 Topic 和 Partition,如下图所示:

进入到其中的任何一个目录(如 consumer-delay-test-0),有如下文件:
-rw-r—r— 1 zhaoxiaofa wheel 10485760 1 11 11:13 00000000000000000000.index
-rw-r—r— 1 zhaoxiaofa wheel 0 1 11 11:13 00000000000000000000.log
-rw-r—r— 1 zhaoxiaofa wheel 10485756 1 11 11:13 00000000000000000000.timeindex
-rw-r—r— 1 zhaoxiaofa wheel 8 1 11 11:13 leader-epoch-checkpoint
-rw-r—r— 1 zhaoxiaofa wheel 43 1 11 11:13 partition.metadata
其中,“.index” 文件和 “.log” 文件分别表示为 Segment 索引文件和数据文件。
因为刚创建 Topic ,没有往该 Topic 写入任何数据,所以只有一个 “.index” 文件和 “.log” 文件,现在尝试往这个 Topic 中写入大量的数据,看看会有什么现象。
写入完成后,在查看该目录,如下:
-rw-r—r— 1 zhaoxiaofa wheel 548176 1 11 15:04 00000000000000000000.index
-rw-r—r— 1 zhaoxiaofa wheel 1073733333 1 11 15:04 00000000000000000000.log
-rw-r—r— 1 zhaoxiaofa wheel 242484 1 11 15:04 00000000000000000000.timeindex
-rw-r—r— 1 zhaoxiaofa wheel 10485760 1 11 15:04 00000000000023633685.index
-rw-r—r— 1 zhaoxiaofa wheel 511265337 1 11 15:04 00000000000023633685.log
-rw-r—r— 1 zhaoxiaofa wheel 10 1 11 15:04 00000000000023633685.snapshot
-rw-r—r— 1 zhaoxiaofa wheel 10485756 1 11 15:04 00000000000023633685.timeindex
-rw-r—r— 1 zhaoxiaofa wheel 8 1 11 11:13 leader-epoch-checkpoint
-rw-r—r— 1 zhaoxiaofa wheel 43 1 11 11:13 partition.metadata
发现新增了 00000000000023633685.index 和 00000000000023633685.log 文件,并且 Broker 的日志文件中打印了如下日志:
[Log partition=consumer-delay-test-0, dir=/tmp/kafka-logs] Rolled new log segment at offset 23633685 in 170 ms. (kafka.log.Log)
上述测试可以说明,在不断往 Topic 里写数据时,Partition 下面会分割成多个 Segment 文件。
3.2 为什么需要 Segment?
假设 Kafka 以 Partition 为最小存储单位,那么当 Producer 不断发送消息,必然会引起 Partition 文件的无限扩张,如果一直往一个文件里面写数据,将对消息文件的维护以及已消费的消息的清理带来严重的影响。
因此,需以 Segment 为单位将 Partition 进一步细分。每个 Partition 相当于一个巨型文件被平均分配到多个大小相等的 Segment 数据文件中。
这种特性也方便 Old Segment 的删除,如果某个 Segment 的消息被全部消费完毕,即可删除掉,方便文件维护,同时也提高了磁盘的利用率。
3.3 Segment 工作原理
这一段可以直接参考美团的文章——Kafka文件存储机制那些事 的 2.2 和 2.3 。
index 存储的其实是消息的元数据,log 存储的才是真正的消息,所以 log 文件的大小远大于 index 文件。
值得注意的是 index 是稀疏索引文件,存储的只是部分消息的元数据,这样可以减少存储空间。
在查询消息的时候,通过 二分查找 定位 index,然后在 log 中搜索到真正的消息。
参考
https://tech.meituan.com/2015/01/13/kafka-fs-design-theory.html