
1. 背景
最近团队里的一个重 Kafka 项目频繁的发生 Rebalance ,导致经常性的出现消息堆积问题,峰值曾堆积过数千万条消息。因此来研究下 Kafka Rebalance 相关的问题。
2. Rebalance时机
当 Kafka 遇到如下四种情况的时候,会触发 Rebalance 机制:
- 消费组成员发生了变更
A:新消费者加入
B:有消费者宕机 - 消费者无法在指定的时间之内完成消息的消费
- 消费组订阅的 Topic 发生了变化
- 订阅的 Topic 的 Partition 发生了变化
对可能出现以上情况的场景进行说明:
- 1A 出现在应用启动的时候,属于正常现象;
- 1B 大多数出现在应用下线的时候,属于正常现象;
- 1B 少部分会出现在 Consumer 长时间没有发送心跳给 Broker,Broker 会认为该 Consumer 异常,会将其剔除出 Consumer Group,触发 Rebalance,大概率属异常现象;
- 2 是因为 Consumer 业务逻辑耗时过大,消费过慢导致的,几乎可以认为是异常现象;
- 3 一般是修改了业务代码,重新部署,属于正常现象;
- 4 一般是中间件团队对 Broker 集群进行操作引起的,比如增加 Topic 的 Partition 数量,属于正常现象;
小结:真正异常的且需要业务开发团队关注的只有两点:心跳机制和消费者业务逻辑。
2.1 心跳机制
心跳机制主要由以下两个参数进行控制:
heartbeat.interval.ms:心跳的间隔时间 默认 3ssession.timeout.ms:超过该值而没有任何心跳发送给 Broker,Broker 会剔除 Consumer,进行 Reblance 默认 45s
按照默认值的配置,连续 15 次没有发送心跳,才会进行 Rebalance,一般只有网络出现故障才会出现这种情况。即使是 Full GC,一般也不会超过 45s。
2.2 消费超时
对于消费主要由以下两个参数进行控制:
max.poll.interval.ms:两次 poll 消息最大间隔时间,超过该值即认为 Consumer 崩溃 默认 5 分钟max.poll.records:一次 poll 消息的最大数量 500
如果在 5 分钟内无法处理掉拉取的消息,就会引发 Rebalance。而事实上,绝大多数 Rebalance 都是因为 Consumer 业务逻辑耗时过大引起的。
2.2.1 Consumer 超时测试
首先创建一个测试 topic(”consumer-delay-test“),分配 4 个 partition,脚本如下:
1 | bin/kafka-topics.sh --create --partitions 4 --replication-factor 1 --topic consumer-delay-test --bootstrap-server localhost:9092 |
创建成功之后在 Kafka 的日志文件中可以看到有四个文件目录,如下:

创建多个 Consumer,消费该 topic,为了更快的看到现象,将 max.poll.interval.ms 的值设置为 1 分钟,消费逻辑中线程 sleep 10s,具体代码如下:
1 | public static void main(String[] args) { |
开始运行后,会发起 join group 的请求,成功 join 之后,会分配消费分区,初始化日志如下(仅节选部分日志):
2022-01-10 16:49:53.620 [Thread-0] INFO o.a.k.c.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-3, groupId=testDelay] Successfully joined group with generation 6
2022-01-10 16:49:53.620 [Thread-1] INFO o.a.k.c.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-2, groupId=testDelay] Successfully joined group with generation 6
2022-01-10 16:49:53.621 [Thread-2] INFO o.a.k.c.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-1, groupId=testDelay] Successfully joined group with generation 6
2022-01-10 16:49:53.621 [Thread-2] INFO o.a.k.c.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-1, groupId=testDelay] Setting newly assigned partitions: consumer-delay-test-0, consumer-delay-test-1
2022-01-10 16:49:53.621 [Thread-0] INFO o.a.k.c.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-3, groupId=testDelay] Setting newly assigned partitions: consumer-delay-test-3
2022-01-10 16:49:53.622 [Thread-1] INFO o.a.k.c.consumer.internals.ConsumerCoordinator - [Consumer clientId=consumer-2, groupId=testDelay] Setting newly assigned partitions: consumer-delay-test-2
从运行日志中可以看出,consumer-1 消费 patition0和1,consumer-2 消费 patition2,consumer-3 消费 patition3。
在正常消费一段时间后,出现如下 warn 日志:
2022-01-10 16:59:33.488 [kafka-coordinator-heartbeat-thread | testDelay] WARN o.a.k.c.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-3, groupId=testDelay] This member will leave the group because consumer poll timeout has expired. This means the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time processing messages. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.
2022-01-10 16:59:33.488 [kafka-coordinator-heartbeat-thread | testDelay] WARN o.a.k.c.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-2, groupId=testDelay] This member will leave the group because consumer poll timeout has expired. This means the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time processing messages. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.
2022-01-10 16:59:33.490 [kafka-coordinator-heartbeat-thread | testDelay] INFO o.a.k.c.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-2, groupId=testDelay] Member consumer-2-f3cac25b-3cc2-40f8-9514-af8e550d8dba sending LeaveGroup request to coordinator localhost:9092 (id: 2147483647 rack: null)
2022-01-10 16:59:33.490 [kafka-coordinator-heartbeat-thread | testDelay] INFO o.a.k.c.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-3, groupId=testDelay] Member consumer-3-ba3b3947-2adf-444b-92c1-34a444065b14 sending LeaveGroup request to coordinator localhost:9092 (id: 2147483647 rack: null)
2022-01-10 16:59:33.556 [kafka-coordinator-heartbeat-thread | testDelay] WARN o.a.k.c.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-1, groupId=testDelay] This member will leave the group because consumer poll timeout has expired. This means the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time processing messages. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.
2022-01-10 16:59:33.556 [kafka-coordinator-heartbeat-thread | testDelay] INFO o.a.k.c.consumer.internals.AbstractCoordinator - [Consumer clientId=consumer-1, groupId=testDelay] Member consumer-1-fac44445-0d07-4a7d-bd1f-10e446354af8 sending LeaveGroup request to coordinator localhost:9092 (id: 2147483647 rack: null)
从告警日志中可以看出,Consumer 会离开 Group,原因是 poll 请求超时。告警中提供的解决方案是加大 max.poll.interval.ms 或者减少 max.poll.records 。
2.2.2 消费配置建议
在生产环境中,不建议因为担心 Rebalance 而调高 max.poll.interval.ms 减少 max.poll.records ,一般采用默认值即可,最重要的其实是优化 Consumer 的消费逻辑,减少耗时。否则,仅靠调整这两个参数意义不大。
2.3 详细配置说明
2.1 和 2.2 中的配置参数详细说明可参见之前的文章——Kafka调优与详细参数说明 。
3. Rebalance原理
文章该部分主要摘抄于《参考资料》中的 1。
3.1 Consumer Group 状态机
要弄清楚 Rebalance 原理,首先要了解 Consumer Group 状态机。Kafka 设计 Consumer Group 状态机的目的是帮助 Coordinator 完成 Rebalance。
Consumer Group 有 5 种状态,其流转图如下(图片来源于网络):
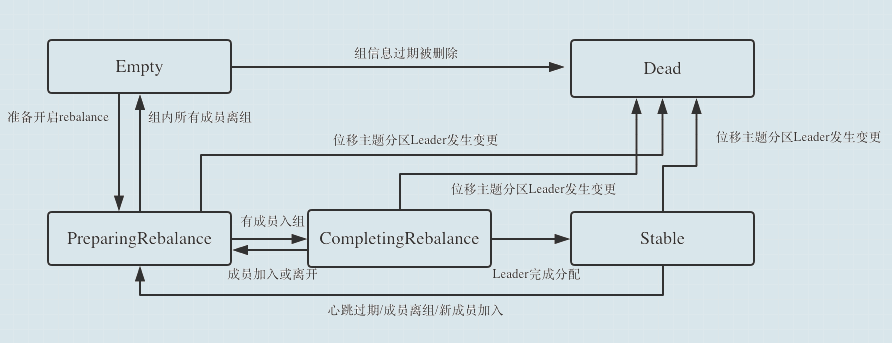
- 一个消费者组最开始是 Empty 状态
- 在 Rebalance 开启后,会首先置于 PreparingRebalance 等待 Consumer 成员加入
- 之后变更到 CompletingRebalance 等待 Consumer Leader 分配分区消费方案
- 分配完成之后,状态流转到 Stable ,此时 Rebalance 结束
- 当有成员变动时,消费者组状态从 Stable 变为 PreparingRebalance
- 此时所有现存成员需要重新申请加入 Consumer Group
- 当所有组成员都退出组后,消费者组状态为 Empty
- 消费者组处于 Empty 状态,Kafka 会定期自动删除过期 offset
Rebalance 过程分为两步:JoinGroup 和 SyncGroup。
3.2 JoinGroup
在这一步中,所有 Consumer 向 Coordinator 发送 JoinGroup 的请求,Coordinator 会在 Consumer 中选择一个作为 Leader,并将所有 Consumer 的信息发送给 Leader,由 Leader 进行消费分区的分配。
注意:Coordinator 是 Broker 中的概念,Leader 是 Consumer 客户端的概念。
流程图大致如下(图片来源于网络):
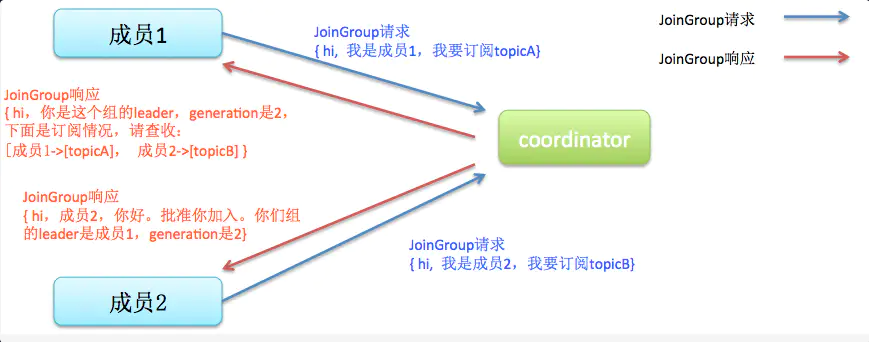
3.3 SyncGroup
在 JoinGroup 之后,选举出来的 Leader 会分配好消费方案,然后通过 SyncGroup 请求将分区消费方案发送给 Coordinator,非 Leader 也会发 SyncGroup 请求,只是内容为空。
Coordinator 接收到分配方案之后会把方案塞进 SyncGroup 的 Response 中发给各个 Consumer。这样各 Consumer 都知道自己应该消费哪些分区了。
流程图大致如下(图片来源于网络):

3.3 Rebalance场景
3.3.1 新成员加入(应用上线)
流程图大致如下(图片来源于网络,网络来自于《Apache Kafka 实战》):

图中,从成员2发起 JoinGroup 请求至成员2收到 SyncGroup 响应,期间 Consumer 处于 STW 状态,不会消费消息。
3.3.2 成员注定离开(应用下线)

3.3.3 成员奔溃离开(消费超时)

4. 生产环境故障处理
4.1 不知名topic业务代码引起的故障
4.1.1 告警
有一次收到了线上的电话告警,消息量大的一个 topic (消息量约 5 万/s)线上堆积了上千万条消息。在 Kafka 监控台可以看到集群在疯狂的 Rebalance ,几乎是 Rebalance 一次完毕之后立马又开始 Rebalance。
因为监控聚合后具体时间间隔不够精准,于是搜索了 Rebalance 相关的日志,日志大致如下:
August 15th 2020, 11:18:49.082 message:2020-08-15 03:18:48, INFO, o.a.k.c.c.i.AbstractCoordinator , 916, maybeLeaveGroup [Consumer clientId=consumer-####-53, groupId=####] Member consumer-###### sending LeaveGroup request to coordinator ####### (id: ##### rack: null) due to consumer poll timeout has expired. This means the time between subsequent calls to poll() was longer than the configured max.poll.interval.ms, which typically implies that the poll loop is spending too much time processing messages. You can address this either by increasing max.poll.interval.ms or by reducing the maximum size of batches returned in poll() with max.poll.records.
因为涉及生产环境机器,引用中 “##” 为打码。
分析日志发现,大约隔了 5 分钟左右,便发生一次 Rebalance,说明集群刚开始消费,然后消费的消息就卡住了,导致超过 session.timeout.ms 的设置,再次 Rebalance。
4.1.2 定位
对线上机器 Jstack 之后,搜索该 topic 的消费堆栈时,却没有发现什么问题。此时,遵循先止血再分析的原则,在消费逻辑中打开异步线程池消费的开关,开启之后,从监控看,消费速度明显上涨,我们以为问题已经得到解决,没想到,不到 5 分钟,集群再次 Rebalance,消费再次跌零。
此时的我,一脸懵逼,已经开启异步线程池消费了呀,消费逻辑里就是把消息解析出来,扔到线程池里,然后就 ack,怎么可能消费超时呢?
正在迷茫之际,看到企业微信又跳出来一个告警,某个不知名 topic,堆积了 2 条消息。对,你没有看错,2 条消息!!!看到这个告警,如梦初醒。
导致集群疯狂 Rebalance 的不一定就是消息量最大、堆积最多的那个 topic 呀!
导致集群疯狂 Rebalance 的不一定就是消息量最大、堆积最多的那个 topic 呀!
导致集群疯狂 Rebalance 的不一定就是消息量最大、堆积最多的那个 topic 呀!
再次线上 Jstack,搜索堆积了 2 条消息的那个消息者堆栈信息,定位到了阻塞的那行代码。同时,通过 uid 关键字在 kibana 中搜索相关日志。发现该 uid 下面挂了 3 万个设备,而这个不知名的 topic 的消费逻辑里面是遍历设备列表,进行一系列的操作。
很明显,这 3 万个设备的后续逻辑是无法在 5 分钟内完成的,因此,无论 Rebalance 后哪个 Consumer 消费这条消息,都无法完全,只会再次触发 Rebalance。
4.1.3 处理
至此,问题已定位到,“前辈”写下的代码终有一天会在你的手里爆发。于是修改代码,将消费逻辑扔到线程池里,提紧急发布,该问题在发布之后得以解决。
4.1.4 感悟
对于自己负责的系统,边边角角都要照顾到,尤其是容易出现故障的地方。有时候,边缘业务也会对系统造成致命伤害。
4.2 请求三方授权接口耗时过高导致的故障
4.2.1 告警
同样是一次线上 Kafka 消息堆积的电话告警,这次吸收了之前的经验后,首先排查是否有其他 topic 也出现了消息堆积,最终确认没有,确实是只有流量最大的 topic 消息堵塞了。
4.2.2 定位
于是,找到对应堆积的 partition 对应的机器,Jstack 搜索对应 Consumer 的堆栈信息,定位到了阻塞在对外接口的 Http 请求上。

4.2.3 处理
问题处理很简单,打开异步消费的开关即可,打开后线上立马恢复。
4.2.4 后续
在处理完问题之后,后面分析了为什么会导致 http 请求阻塞这么久,后面在看代码的时候,发现了下面一坨代码,我震惊了。

应该是因为笔误的原因,原先写代码的同学将 http 的超时时间设置为了 20000s,即 5.5 小时。这就是消息能阻塞如此之久的原因。你永远不知道你的前辈会给你准备什么样的惊喜。
备注:后面我们对 OkHttp 做了详细的监控和参数调优,该类型问题已全部解决。
5. 如何避免 Rebalance
5.1 Rebalance 的危害
先说说 Rebalance 的危害,大概如下:
- Rebalance 影响 Consumer 端 TPS,在 Rebalance 期间,Consumer 会停下手头的事情,什么也干不了,类似于 GC 中的 Stop The World。
- Rebalance 很慢,尤其是当 Group 下 Consumer 成员很多的时候,以我经历的项目为例,15 台机器,Rebalance 需要 5s。
- Rebalance 效率不高。当前 Kafka 的设计机制决定了每次 Rebalance 时,Group 下的所有成员都要参与进来,而且通常不会考虑局部性原理,但局部性原理对提升系统性能是特别重要的。
5.2 怎样尽可能避免 Rebalance
网上有很多文章说需要调节参数的,比如调节 heartbeat.interval.ms 和session.timeout.ms ,或者调节 max.poll.interval.ms 和 max.poll.records。
但是个人认为,大多数情况下,我们根本不需要调节以上几个参数,使用默认值即可。
真正应该去做的如下:
- 优化业务逻辑代码,降低消费 RT
- Kafka 的业务消费逻辑一定要进行消费耗时监控,提前观察哪些 topic 对应的消费业务逻辑可能会存在极端耗时的情况。往往一个不起眼的,流量很小的,平时不大注意的 topic 在某些时刻就能让整个 Consumer 集群陷入崩溃的边缘
- 凡是涉及调用第三方接口的,一定要做相关监控,不仅仅局限于 Kafka 链路,应用的任何链路都需要
监控、监控、监控!!!
优化、优化、优化!!!