
1. 前言
Kafka 的调优包含四部分,操作系统、服务端、客户端。对于业务开发人员来讲,需要着重关注客户端的调优,操作系统和服务端一般由运维和中间件同学负责。
2. 目标
对 Kafka 而言,调优一般是指吞吐量和延时。
3. 操作系统、服务端
操作系统和服务端的调优了解下,主要是遇到问题能和运维、中间件同学对话,别让人觉得你啥都不懂,懒得理你。从个人经历来看,你懂的越多,运维、中间件同学越乐意给你答疑。
3.1 操作系统
操作系统的调优本人也不懂,但是 Kafka 的零拷贝依赖 Page Cache,所以预留给 Kafka 的 Page Cache 要足够,可以通过 Broker 端参数 log.segment.bytes 进行配置。
3.2 服务端
3.2.1 JVM
因为 Kafka 也是 Java 应用,所以,JVM 调优是必须的。JVM 的调优主要涉及 GC 收集器的选择和 JVM 参数设置,Kafka 肯定部署在大内存的机器上,所以收集器选择 G1 而不是 CMS。
使用 G1 时要注意大对象问题,可以适当地增加区域大小,对应的 JVM 参数为 -XX:+G1HeapRegionSize。
3.2.3 Broker
参数 num.replica.fetchers 表示的是 Follower 副本用多少个线程来拉取消息,默认使用 1 个线程。一般可以调大该值(小于 CPU 核数),加快 Follower 副本的同步速度,尤其是配置了 acks=all 的 Producer 程序,吞吐量会受副本同步性能的影响。
4. 客户端
总体思路如下:
- 不要频繁地创建 Producer 和 Consumer 对象实例。
- 用完及时关闭,这些对象底层会创建很多物理资源。
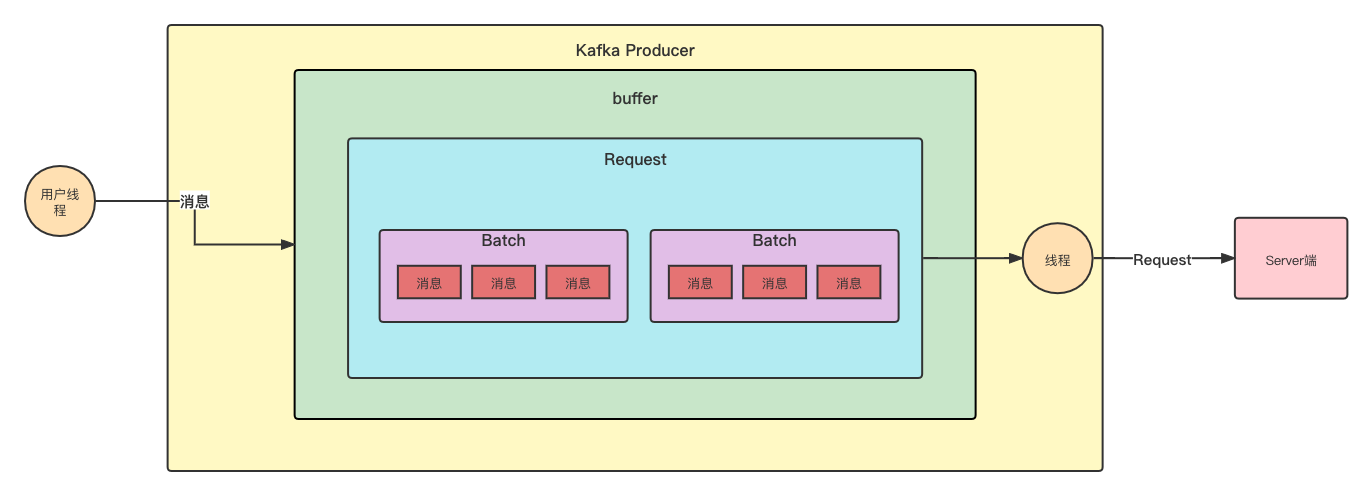
- 合理利用多线程。Kafka 的 Producer 是线程安全的,可以多线程共用;而 Consumer 虽不是线程安全的,但同样有两种多线程使用方式。
实际使用过程中,可以对参数设置进行调优,详细参数说明见官网 。其中,重要但是基本不可调的参数略过。
4.1 Producer参数
buffer.memory 默认值:32M
The total bytes of memory the producer can use to buffer records waiting to be sent to the server. If records are sent faster than they can be delivered to the server the producer will block for
max.block.msafter which it will throw an exception.This setting should correspond roughly to the total memory the producer will use, but is not a hard bound since not all memory the producer uses is used for buffering. Some additional memory will be used for compression (if compression is enabled) as well as for maintaining in-flight requests.
多线程共用 Producer 时,可能会出现缓冲区不够的情况,此时会 block 住,block 时间若超过 max.block.ms ,会抛出异常(TimeoutException:Failed to allocate memory within the configured max blocking time)。
可以通过调大该参数提高 Producer 的吞吐量。
题外话:in-flight requests 指的是发送出去但是还没有收到响应的请求。
max.block.ms 默认值:1分钟
The configuration controls how long the
KafkaProducer‘ssend(),partitionsFor(),initTransactions(),sendOffsetsToTransaction(),commitTransaction()andabortTransaction()methods will block. Forsend()this timeout bounds the total time waiting for both metadata fetch and buffer allocation (blocking in the user-supplied serializers or partitioner is not counted against this timeout). ForpartitionsFor()this timeout bounds the time spent waiting for metadata if it is unavailable. The transaction-related methods always block, but may timeout if the transaction coordinator could not be discovered or did not respond within the timeout.
Producer 很多 API 都依靠该值来控制 block 的最大时间。对 send 方法而言,该值规定了获取元数据和申请缓存去的时间(与上面 buffer.memory 的解释相呼应);对 partitionsFor 方法而言,限定了元数据不可用时获取元数据的时间;对事物相关的方法而言,规定了无法发现协调者或协调者无法响应的时间。
batch.size 默认值:16Kb
The producer will attempt to batch records together into fewer requests whenever multiple records are being sent to the same partition. This helps performance on both the client and the server. This configuration controls the default batch size in bytes.
No attempt will be made to batch records larger than this size.
Requests sent to brokers will contain multiple batches, one for each partition with data available to be sent.
A small batch size will make batching less common and may reduce throughput (a batch size of zero will disable batching entirely). A very large batch size may use memory a bit more wastefully as we will always allocate a buffer of the specified batch size in anticipation of additional records.
批处理大小,适当调大该值,可以提高吞吐量。
linger.ms 默认值:0
The producer groups together any records that arrive in between request transmissions into a single batched request. Normally this occurs only under load when records arrive faster than they can be sent out. However in some circumstances the client may want to reduce the number of requests even under moderate load. This setting accomplishes this by adding a small amount of artificial delay—that is, rather than immediately sending out a record the producer will wait for up to the given delay to allow other records to be sent so that the sends can be batched together. This can be thought of as analogous to Nagle’s algorithm in TCP. This setting gives the upper bound on the delay for batching: once we get
batch.sizeworth of records for a partition it will be sent immediately regardless of this setting, however if we have fewer than this many bytes accumulated for this partition we will ‘linger’ for the specified time waiting for more records to show up. This setting defaults to 0 (i.e. no delay). Settinglinger.ms=5, for example, would have the effect of reducing the number of requests sent but would add up to 5ms of latency to records sent in the absence of load.
这个参数和 batch.size 都是用于控制消息发送的,如果消息量达到 batch.size 会被立刻发送到 Server,如果时间达到 linger.ms 消息也会被发出。
适当调大该值,可以提高吞吐量,但是消息延时也会更高。
max.request.size 默认值:1M
The maximum size of a request in bytes. This setting will limit the number of record batches the producer will send in a single request to avoid sending huge requests. This is also effectively a cap on the maximum uncompressed record batch size. Note that the server has its own cap on the record batch size (after compression if compression is enabled) which may be different from this.
定义了单次请求发送消息的最大值(压缩前),Server 端有类似的参数定义(压缩后)。
buffer.memory、batch.size、 max.request.size 三者大小关系
注意:该图仅表示三者大小关系,并不代表内存存储结构。
compression.type 默认值:none
The compression type for all data generated by the producer. The default is none (i.e. no compression). Valid values are
none,gzip,snappy,lz4, orzstd. Compression is of full batches of data, so the efficacy of batching will also impact the compression ratio (more batching means better compression).
如果希望提高吞吐量,可以使用压缩算法,减少网络 I/O,但是启用压缩算法会增大延时,毕竟压缩操作要消耗 CPU 时间。可根据业务自行选择,目前比较好的两个算法是 LZ4 和 zstd。
注意:如果 Broker 端指定了算法,Producer 最好和 Broker 的压缩算法保持一致,否则 Broker 在接受到消息之后会解压缩后再次按照 Broker 的压缩算法进行压缩,会导致 Broker 的 CPU 莫名的高。但是一般情况下,Broker 的压缩算法 producer,即 Broker 端会“尊重”Producer 端使用的压缩算法。Producer 配置前最好和中间件的同学确认好。
acks 默认值:all
The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are allowed:
acks=0If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and theretriesconfiguration will not take effect (as the client won’t generally know of any failures). The offset given back for each record will always be set to-1.acks=1This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.acks=allThis means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting.
如果希望生产者不丢消息,可以设置为 all,但是对应吞吐量会降低。
connections.max.idle.ms 默认值:9分钟
Close idle connections after the number of milliseconds specified by this config.
retries 默认值:int 最大值
Setting a value greater than zero will cause the client to resend any record whose send fails with a potentially transient error. Note that this retry is no different than if the client resent the record upon receiving the error. Allowing retries without setting
max.in.flight.requests.per.connectionto 1 will potentially change the ordering of records because if two batches are sent to a single partition, and the first fails and is retried but the second succeeds, then the records in the second batch may appear first. Note additionally that produce requests will be failed before the number of retries has been exhausted if the timeout configured bydelivery.timeout.msexpires first before successful acknowledgement. Users should generally prefer to leave this config unset and instead usedelivery.timeout.msto control retry behavior.
这个重试和 Producer 客户端重新发送消息并没有本质区别,如果 max.in.flight.requests.per.connection 值不为 1,允许重试可能会导致消息顺序错乱(本质是 Kafka 批处理导致的)。
如果请求总时间超过 delivery.timeout.ms 的配置,不会再重试。官方推荐使用者使用默认值,通过 delivery.timeout.ms 来控制成功行为,这也是为什么该值默认 int 最大值。
delivery.timeout.ms 默认值:2分钟
An upper bound on the time to report success or failure after a call to
send()returns. This limits the total time that a record will be delayed prior to sending, the time to await acknowledgement from the broker (if expected), and the time allowed for retriable send failures. The producer may report failure to send a record earlier than this config if either an unrecoverable error is encountered, the retries have been exhausted, or the record is added to a batch which reached an earlier delivery expiration deadline. The value of this config should be greater than or equal to the sum ofrequest.timeout.msandlinger.ms.
max.in.flight.requests.per.connection 默认值:5
The maximum number of unacknowledged requests the client will send on a single connection before blocking. Note that if this config is set to be greater than 1 and
enable.idempotenceis set to false, there is a risk of message re-ordering after a failed send due to retries (i.e., if retries are enabled).
客户端在阻塞前在单个连接上发送的未被确认的请求的最大数量。如果该值设置大于 1 且 enable.idempotence 设置为 false,消息可能在重试时乱序。
enable.idempotence 默认值:true
When set to ‘true’, the producer will ensure that exactly one copy of each message is written in the stream. If ‘false’, producer retries due to broker failures, etc., may write duplicates of the retried message in the stream. Note that enabling idempotence requires
max.in.flight.requests.per.connectionto be less than or equal to 5 (with message ordering preserved for any allowable value),retriesto be greater than 0, andacksmust be ‘all’. If these values are not explicitly set by the user, suitable values will be chosen. If incompatible values are set, aConfigExceptionwill be thrown.
当设置为 “true “时,Producer 将确保每条消息有一份副本被写入流中。如果设置为 “false”,Producer 由于失败重试,可能会在流中写入重试消息的副本。所以该参数和重试消息的顺序性相关。
使用前提条件:
max.in.flight.requests.per.connection<= 5 &&retries> 0 &&acks== ‘false’
retry.backoff.ms 默认值:1秒
The amount of time to wait before attempting to retry a failed request to a given topic partition. This avoids repeatedly sending requests in a tight loop under some failure scenarios.
重试间隔时间,一般使用默认值即可。
关于重试的总结
综上,如果想重试且让消息不乱序,max.in.flight.requests.per.connection 必须设置为1,且 enable.idempotence 必须设置为 true。此时吞吐量会下降。
request.timeout.ms 默认值:30秒
The configuration controls the maximum amount of time the client will wait for the response of a request. If the response is not received before the timeout elapses the client will resend the request if necessary or fail the request if retries are exhausted. This should be larger than
replica.lag.time.max.ms(a broker configuration) to reduce the possibility of message duplication due to unnecessary producer retries.
一次请求等待响应的最大时间(包含重试),该值需要比 broker 配置中的 replica.lag.time.max.ms (follower 从 leader 同步数据的时间)大。
4.2 Consumer参数
fetch.min.bytes 默认值:1
The minimum amount of data the server should return for a fetch request. If insufficient data is available the request will wait for that much data to accumulate before answering the request. The default setting of 1 byte means that fetch requests are answered as soon as a single byte of data is available or the fetch request times out waiting for data to arrive. Setting this to something greater than 1 will cause the server to wait for larger amounts of data to accumulate which can improve server throughput a bit at the cost of some additional latency.
拉取请求的最小数据量,默认值 1 byte,即只要有数据,就会拉取,如果增大该值,会增大吞吐量,但是同时也会增高延时。
fetch.max.bytes 默认值:50M
The maximum amount of data the server should return for a fetch request. Records are fetched in batches by the consumer, and if the first record batch in the first non-empty partition of the fetch is larger than this value, the record batch will still be returned to ensure that the consumer can make progress. As such, this is not a absolute maximum. The maximum record batch size accepted by the broker is defined via
message.max.bytes(broker config) ormax.message.bytes(topic config). Note that the consumer performs multiple fetches in parallel.
该参数定义了批量拉取的最大数据量,但是该值并不绝对,如果第一条数据的大小已经超过了该配置值,会返回第一条,并不会报错。
max.partition.fetch.bytes 默认值:1M
The maximum amount of data per-partition the server will return. Records are fetched in batches by the consumer. If the first record batch in the first non-empty partition of the fetch is larger than this limit, the batch will still be returned to ensure that the consumer can make progress. The maximum record batch size accepted by the broker is defined via
message.max.bytes(broker config) ormax.message.bytes(topic config). See fetch.max.bytes for limiting the consumer request size.
该参数定义单个 partition 批量拉取最大数据量。
fetch.max.wait.ms 默认值:500ms
The maximum amount of time the server will block before answering the fetch request if there isn’t sufficient data to immediately satisfy the requirement given by fetch.min.bytes.
这个参数定义在拉取数据时最大等待时间,防止消费延时过高,一般和 fetch.min.bytes 往往配合使用。
数据量达到 fetch.min.bytes 的配置值或者等待时间达到 fetch.max.wait.ms 都会促使 Consumer 拉取消息。
heartbeat.interval.ms 默认值:3秒
The expected time between heartbeats to the consumer coordinator when using Kafka’s group management facilities. Heartbeats are used to ensure that the consumer’s session stays active and to facilitate rebalancing when new consumers join or leave the group. The value must be set lower than
session.timeout.ms, but typically should be set no higher than 1/3 of that value. It can be adjusted even lower to control the expected time for normal rebalances.
心跳间隔时间,需要小于 session.timeout.ms * 1/3 ,一般使用默认值。
session.timeout.ms 默认值:45秒
The timeout used to detect client failures when using Kafka’s group management facility. The client sends periodic heartbeats to indicate its liveness to the broker. If no heartbeats are received by the broker before the expiration of this session timeout, then the broker will remove this client from the group and initiate a rebalance. Note that the value must be in the allowable range as configured in the broker configuration by
group.min.session.timeout.msandgroup.max.session.timeout.ms.
超过该值而没有任何心跳发送给 Broker,Broker 会剔除 Consumer,进行 Reblance 。
auto.offset.reset 默认值:latest
What to do when there is no initial offset in Kafka or if the current offset does not exist any more on the server (e.g. because that data has been deleted):
- earliest: automatically reset the offset to the earliest offset
- latest: automatically reset the offset to the latest offset
- none: throw exception to the consumer if no previous offset is found for the consumer’s group
- anything else: throw exception to the consumer.
一般选默认值即可。
enable.auto.commit 默认值:true
If true the consumer’s offset will be periodically committed in the background.
一般填 false。
max.poll.interval.ms 默认值:5分钟
The maximum delay between invocations of poll() when using consumer group management. This places an upper bound on the amount of time that the consumer can be idle before fetching more records. If poll() is not called before expiration of this timeout, then the consumer is considered failed and the group will rebalance in order to reassign the partitions to another member. For consumers using a non-null
group.instance.idwhich reach this timeout, partitions will not be immediately reassigned. Instead, the consumer will stop sending heartbeats and partitions will be reassigned after expiration ofsession.timeout.ms. This mirrors the behavior of a static consumer which has shutdown.
如果超过该值 Consumer 没有 poll,会 Rebalance ,而对于 group.instance.id 配置不为空的,会再等待 session.timeout.ms 的时间才 Rebalance。
max.poll.records 默认值:500
The maximum number of records returned in a single call to poll(). Note, that
max.poll.recordsdoes not impact the underlying fetching behavior. The consumer will cache the records from each fetch request and returns them incrementally from each poll.
该值定义单个 poll 返回的最大记录数。
注意:这个配置并不会影响 Consumer 底层拉取 Broker 消息的行为,Consumer 拉取消息后会将数据缓存在客户端,这个值只影响每次从缓存中读取消息进行业务处理的数据条数。
需要满足 max.poll.records * 每条消息的业务耗时 > max.poll.interval.ms ,否则容易造成消费过慢集群 Rebalance。
4.3 客户端调优总结
| 客户端 | 调优方式 | 调优结果 |
|---|---|---|
| Producer | 增大batch.size | 吞吐量增大 |
| Producer | 增大linger.ms | 吞吐量增大 |
| Producer | 启用压缩算法 | 吞吐量增大 |
| Producer | ack=0或1 | 吞吐量增大(有丢消息的风险) |
| Producer | 设置压缩算法 | 吞吐量增大 |
| Producer | 多线程共享Producer,增大buffer.memory | 吞吐量增大 |
| Producer | linger.ms=0 | 延迟减小 |
| Producer | 不用压缩算法 | 延迟减小 |
| Consumer | 多线程消费 | 吞吐量增大 |
| Consumer | 增大 fetch.min.bytes | 吞吐量增大 |
| Consumer | fetch.min.bytes=1 | 延迟减小 |
小结:有时候吞吐量和延时这两个指标是互斥的,吞吐量涨了,延时可能就会变大,所以需要根据自身业务场景合理选择是追求高吞吐量还是低延时。
对于绝大多数的业务开发同学来说,需要做的是合理的使用 Kafka 提供的 API,并且合理的配置好各参数。