
1. 前言
其一,在做系统稳定性建设时,对日志进行优化,warn 日志中发现大量的 http 的 SocketTimeOutException,原因是”前辈“在写代码的时候直接 try catch 之后,打了 warn 日志。平时没有过多的关注 warn 日志,其实这个报错应该打 error 日志,需要引起关注。
其二,之前线上出问题排查时发现代码中将 Http 的超时时间误设置为 20 * 1000 s,应该是笔误;同时发现 Http 的 Client 竟然不是单例,每次发送请求都会新创建一个 Client,及其浪费性能。
综上,判断系统中 Http 的使用并不正确,应该还有未知坑没有发现。而系统每日的 Http 请求量过亿,因此,需要调优。
2. 监控
2.1 监控指标及Demo
在 OkHttp 官网的 Events 栏中找到了对应的 Http 请求的监控。引用官方文档中的一张图片。
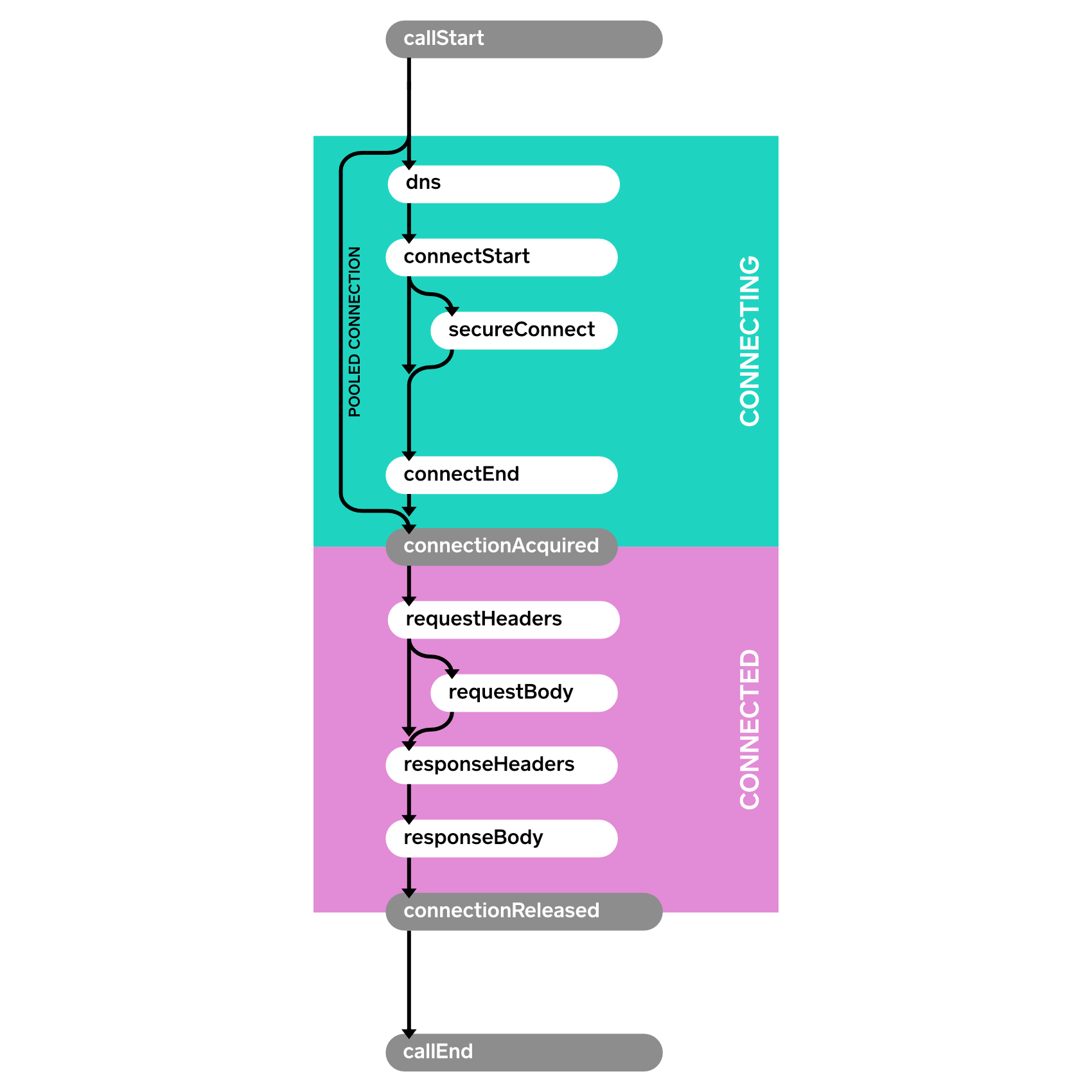
这个图列出了一个 Http 请求的各个阶段,官网上同时给出了通过监听器来监控所有流程,我自己写了个 Demo 。
监听器的代码如下:
1 | public class PrintingEventListener extends EventListener { |
测试类代码如下:
1 | public class OkHttpTest { |
执行结果如下(后面部分省略):
0001 https://www.baidu.com/
0001 0.000 callStart
0001 0.018 dnsStart
0001 0.027 dnsEnd
0001 0.034 connectStart
0001 0.058 secureConnectStart
0001 0.242 secureConnectEnd
0001 0.242 connectEnd
0001 0.244 connectionAcquired
0001 0.246 requestHeadersStart
0001 0.249 requestHeadersEnd
同步Response{protocol=http/1.1, code=200, message=OK, url=https://www.baidu.com/}
0002 https://www.baidu.com/
0002 0.000 callStart
0002 0.000 dnsStart
0002 0.001 dnsEnd
0002 0.002 connectStart
0002 0.018 secureConnectStart
0002 0.097 secureConnectEnd
0002 0.100 connectEnd
0002 0.101 connectionAcquired
0002 0.101 requestHeadersStart
0002 0.101 requestHeadersEnd
同步Response{protocol=http/1.1, code=200, message=OK, url=https://www.baidu.com/}
2.2 线上监控
在生产环境中,我们需要将 Demo 中的打印替换成 Trace 打点,再结合统一的监控平台,就可以监控每一个环节的具体耗时。
同时,我们对连接量和请求量也进行了打点统计,在监控中发现,请求连接比(请求量/连接量)很小,大概 2~3之间,也就是说,一个连接发送 2~3 个 Http 请求之后就断开了。即 TCP 连接的复用率很低。
于是登录机器查看 TCP 的状态,命令是运维大佬提供的,如下所示:netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
生产环境的执行结果:
ESTABLISHED=500+ TIME_WAIT=18000+
因为当时在生产环境执行的结果没有保存下来,所以我在自己的 Mac 上模拟执行了下:

生产环境的执行结果显示,TIME_WAIT 数量很高,说明大量的 TCP 链接主动关闭。因为和链接有关,所以查看了 Client 链接相关的配置,初步猜测和链接池(ConnectionPool)有关。
查看了 OkHttpClient 构造参数的文档——详见 OkHttpClient 。
因为在构造函数里面有这样一项 ConnectionPool 配置,我们项目中的代码是没有这一行的,示例如下:
1 | builder.connectionPool(new ConnectionPool(5, 5, TimeUnit.MINUTES)); |
第一个参数是 maxIdleConnections,默认值是 5,换言之,我们上万并发的 Http 请求该值使用的是默认值。
因此,Google 了 maxIdleConnections 值设置相关的一些文章,在 Stack Overflow 上找到了相关的内容。
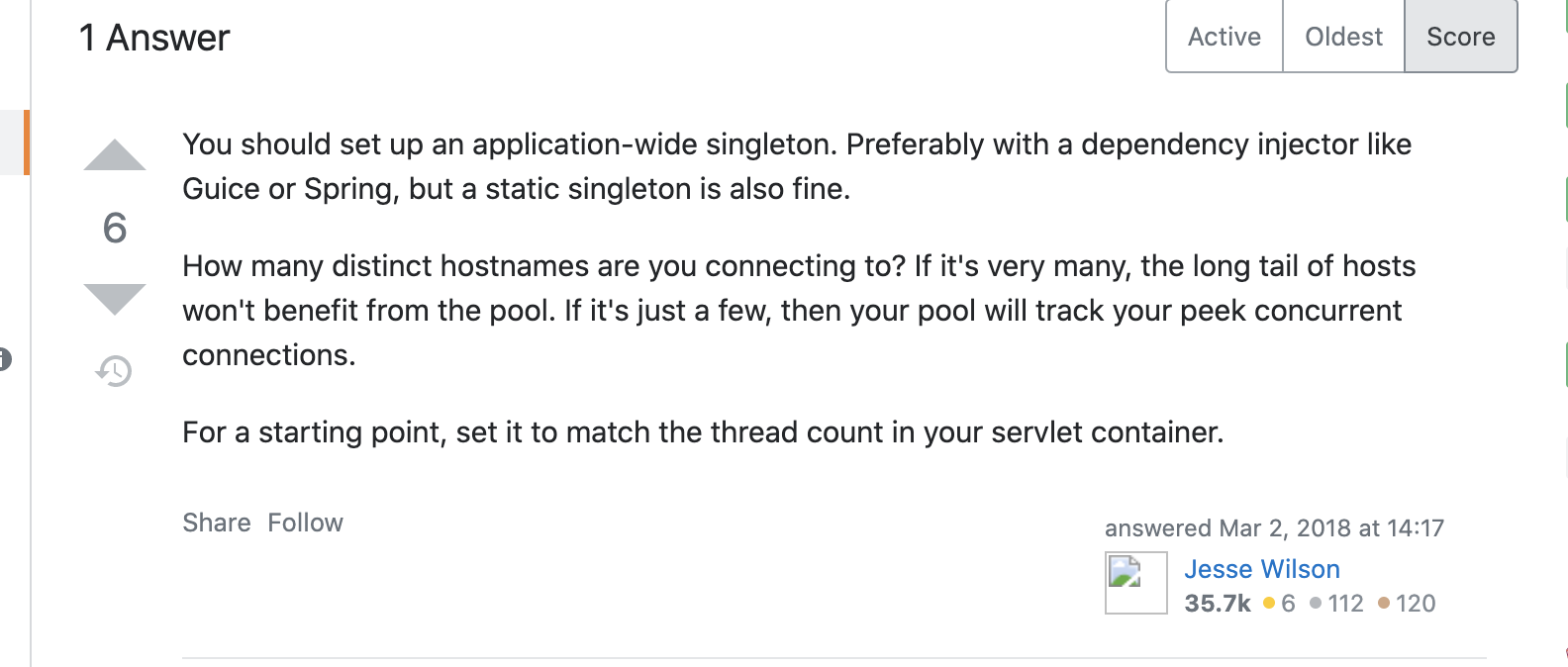
上图是 OkHttp 社区维护人员的回复,For a starting point, set it to match the thread count in your servlet container. 可以将值设置为服务器对应的线程数。详细链接见参考文档。
同时,我 Google 了 ”okhttp connection pool“,同样在 Stack OverFlow 上找到了类似的内容。有开发人员提了一个关于 Connection Pool 的配置,问题如下:

同样是社区维护人员的回复,如下:

这次,这位老哥的回答是,可以直接尝试设置为 256。
国内也有少量文章有涉及该值的配置,文章链接 。

3. 调优
因为我们是在线程池里面异步调用的 Http 请求,所以按照查阅到的文章,可以将 maxIdleConnections 设置为线程池的线程数,因此抱着尝试的心态,设置该值为 200,灰度发布一台机器到线上。
发布后,请求连接比立马涨上去了,达到了 5000,响应的错误日志也没了。整个 Http 接口的成功率几乎接近 100%。
后续不断尝试调整该值大小,针对整点尖刺的场景,将该值调整到 400,目前线上稳定运行,请求连接比约 1万左右。
从线上的效果来看,maxIdleConnections 这个值设置的稍微大点也并没有任何的影响。
总结:
总结一下类似技术栈的调优经验:
1、熟悉一下该技术栈基础知识;
2、了解核心指标,看是否能对核心指标进行监控;
3、线上添加监控,分析监控数据是否合理;
4、根据监控数据且再次收集信息进行优化。
Kafka 的调优和 OkHttp 的调优其实整体思路和流程都是差不多的,不断的进行梳理、监控、优化,形成闭环。
4. 疑问
但是这里,我有一个疑问:
maxIdleConnections 是指“最大空闲链接数”,而我的应用是一个有稳定大流量的系统,基本不怎么可能出现空闲链接。这个在之前线程池调优的过程中有深刻的体会。参考 —— 项目线程池调优 。
那为什么maxIdleConnections 需要设置这么大的值呢?后面在复盘的时候也没有搞清楚根本原因,问题解决了,根因还是没找到。后续有时间还要研究下。
5. 参考
6. 时隔一个月后的更新
时隔一个月后,大致找到了 4 中疑问的答案。再次搜索了相关的资料,发现原来在参考资料 4 中,社区维护人员的一句话让我给忽略掉了。引用如下:
Connections are either active and held by a particular in-flight call, or idle and in the pool. Limit the total number of connections by limiting the number of threads executing HTTP calls. If you’re using
Call.execute()(synchronous) just size your thread pool appropriately. If you’re usingCall.enqueue()(asynchronous) the limits are inDispatcher.
答案就在第一句中,如果一个连接正在发送请求,那它就是活跃的,否则它就是空闲的。按照这样的定义,空闲的连接可太多了,毕竟不是每个连接一直都在执行请求的。
另外还有一个非常关键的点是在阅读清除空闲连接的代码时发现的,代码如下:
1 | if (longestIdleDurationNs >= this.keepAliveDurationNs |
从代码中可见,如果一个连接空闲时间超过了 keepAliveDurationNs,会清除longestIdleConnection;如果空闲的连接数超过了 maxIdleConnections,同样会清除 longestIdleConnection。所以按照默认的配置,只要有超过 5 个空闲连接,就会触发连接清除。因此一旦 maxIdleConnections 值设置过小,就会导致连接复用率较低的情况。